BERT模型的崛起
BERT,这是一种新型的Transformer模型,于2018年问世。短短两年后,即2020年,Google内部已有超过四分之一的应用开始采用BERT模型。深度学习领域的发展速度之快,让人惊叹不已。一个新模型能如此迅速地被广泛使用,充分展示了该技术领域的强大生命力和快速变革。


ML工程师的优化意愿

ML工程师对模型优化充满热情。他们乐于根据硬件和编译器的特性,对DNN模型进行优化。这样做不仅能够提升工作效率,还能让模型在实际应用中展现出更大的效用。

DNN模型的优化基础
DNN模型之所以可优化,一个重要因素是它的程序体量不算太大。一般由数千至数万行PyTorch或TensorFlow代码构成,这样的规模使得操作变得可行。工程师们对代码的调整和修改变得相对简单,进而能够对模型进行优化。
Platform-aware AutoML技术
Google的研究论文阐述了Platform-aware AutoML模型的优化策略。该技术运用了“神经架构搜索”技术,能够使机器在搜索过程中自动发现更高效的神经网络结构。以论文中的CNN1模型为例,经过机器的自动优化,即便在相同的硬件和编译器条件下,其准确率保持不变,但运算效率却提高了原模型的1.6倍。
模型推理优化重点
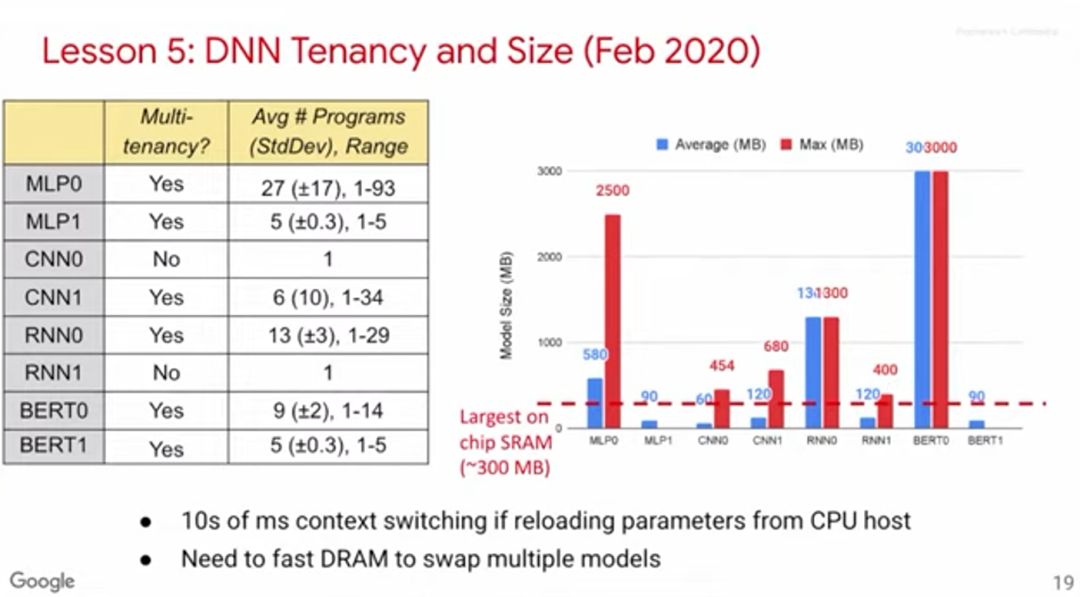
有些论文在探讨模型推理优化时,主要关注数据批次的大小。它们提出,将批次大小设为1可以最小化延迟。但根据MLPerf的数据,我们发现即便批次规模较大,Google的模型也能保持低延迟。这或许是因为这些模型是基于TPU构建的,从而提升了其性能效率。
ML模型优化方向
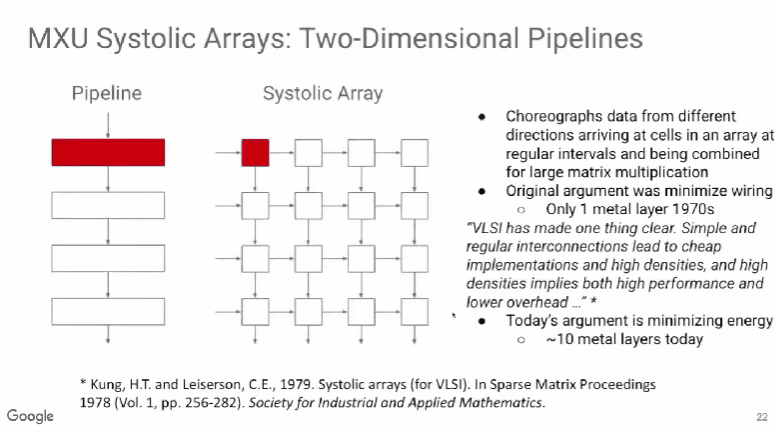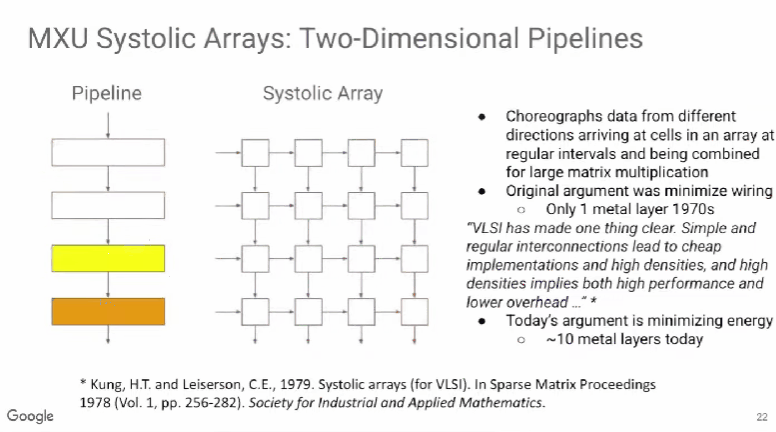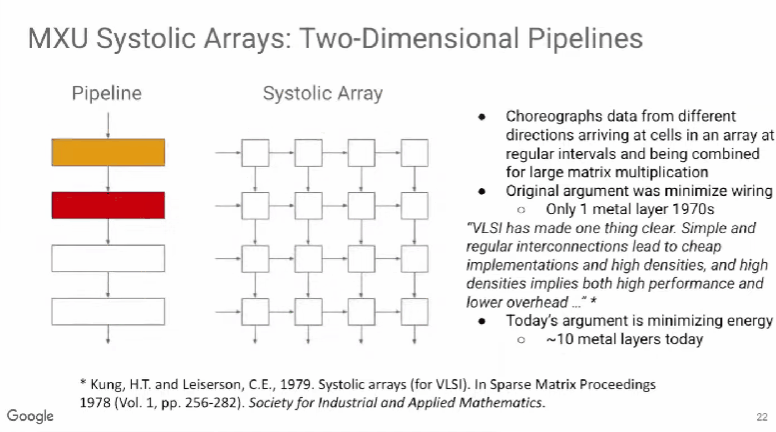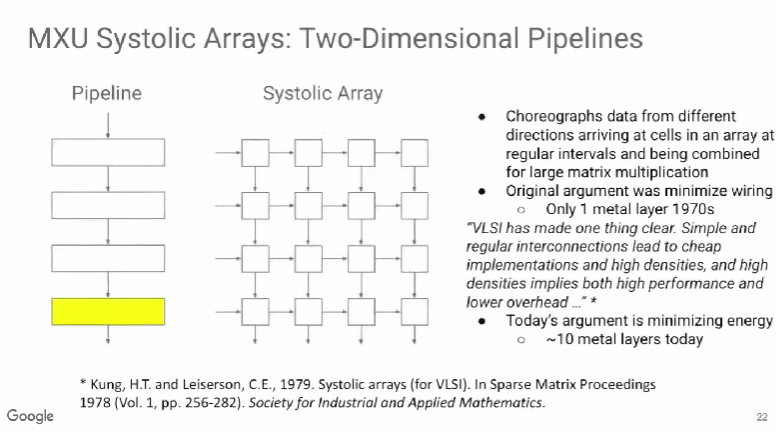
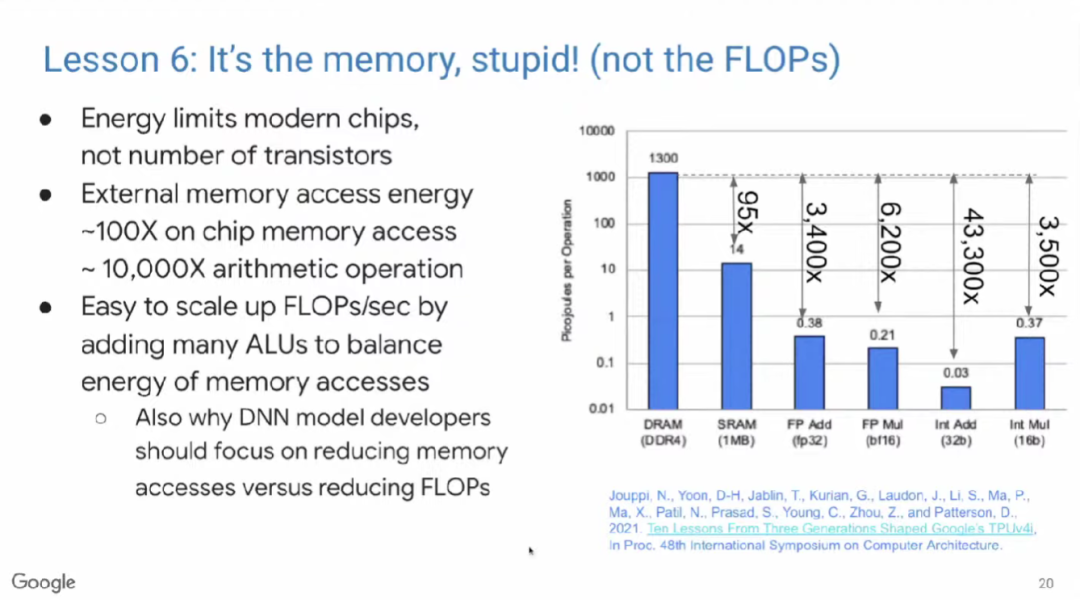
开发ML模型的人员通常试图通过降低浮点运算次数来提升模型性能,但真正有效的是减少内存访问次数。这一发现为模型优化带来了新的视角和路径,促使技术人员在优化时更加重视内存使用效率。

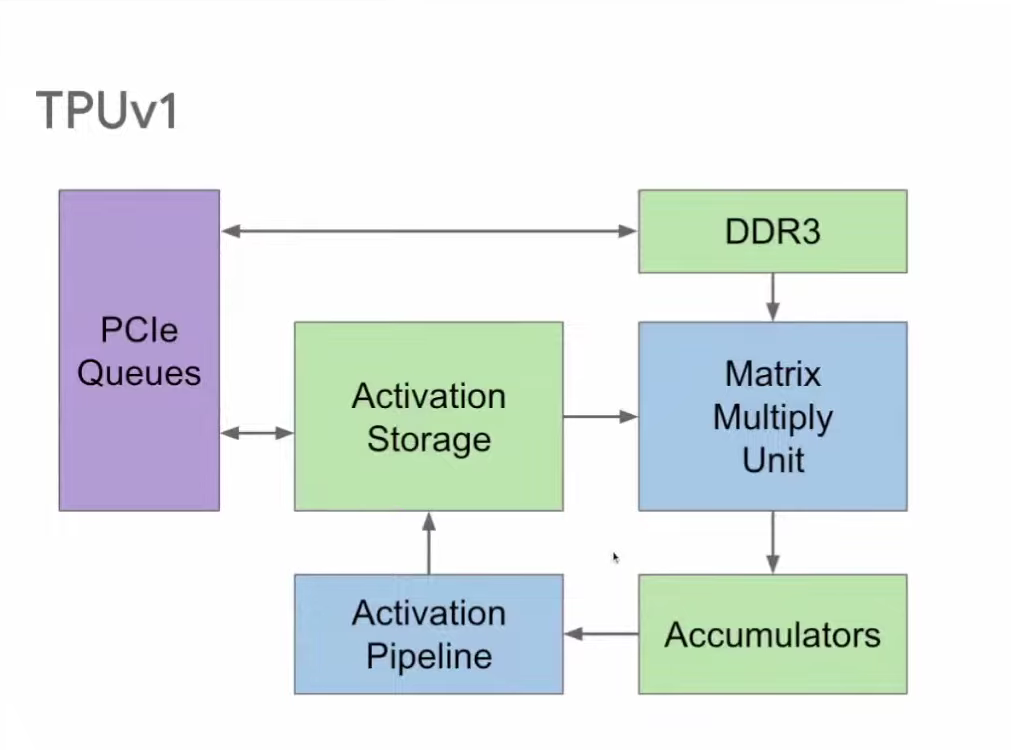
TPU格式的演变
TPU v1仅支持INT8计算,这导致其动态范围不足以满足训练需求。因此,Google在TPU v2中引入了BFloat16这种新型浮点格式,以应用于机器学习计算。这一新格式的应用,有效解决了之前训练过程中的一些难题,并显著提高了训练的效果与性能。
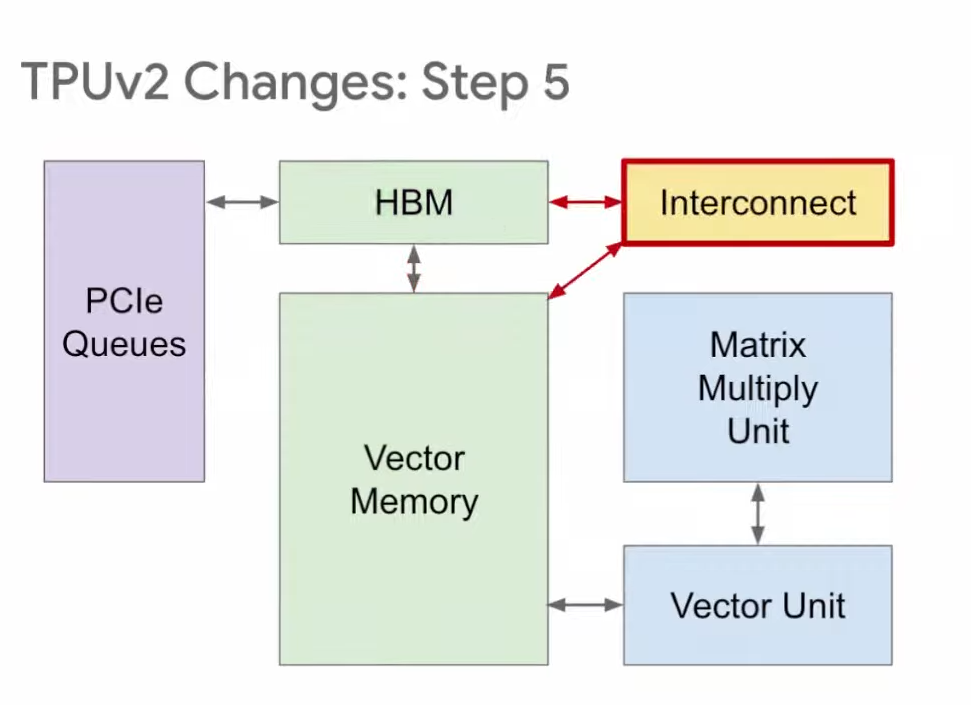
TPU存储区的改进
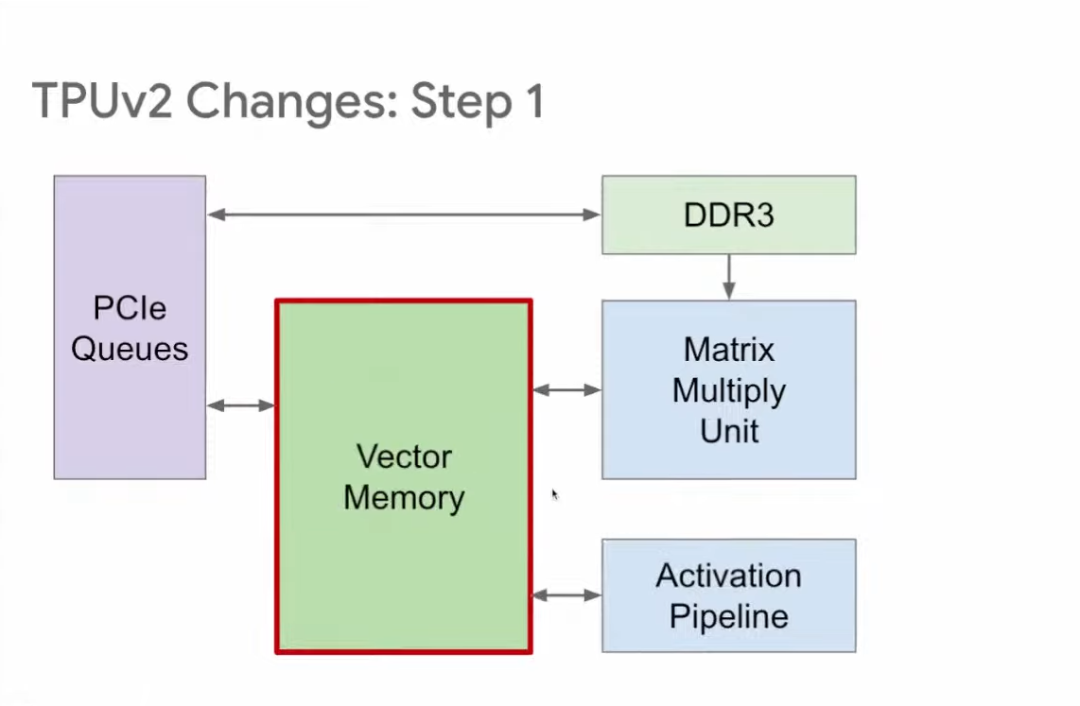
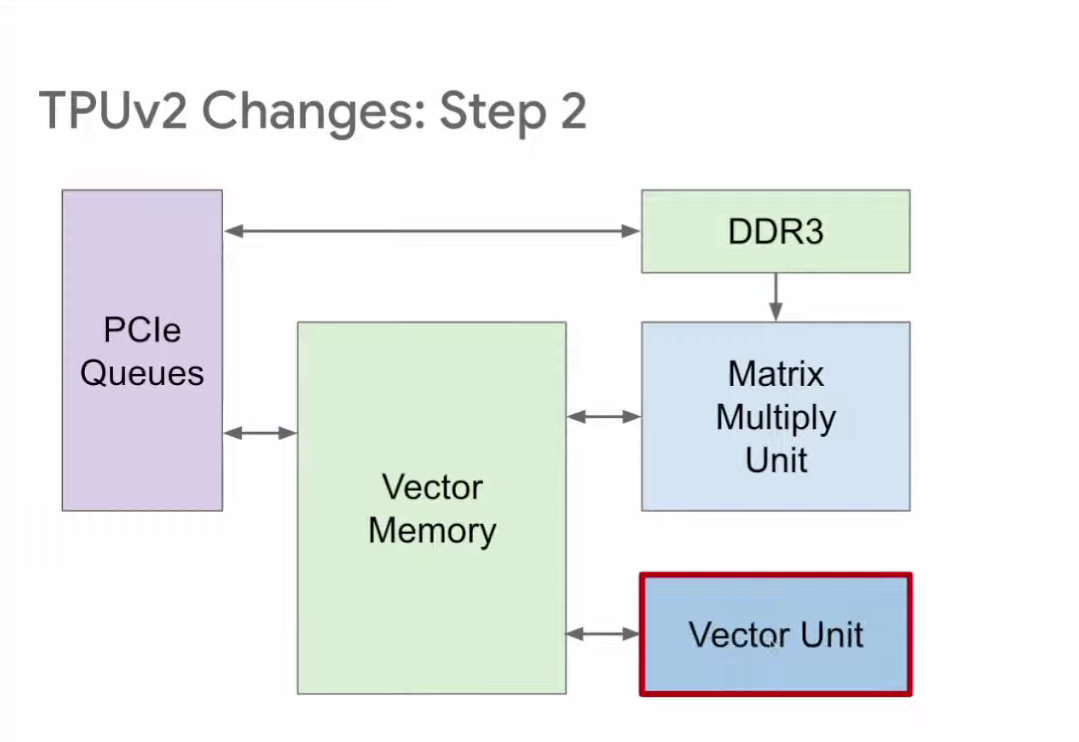
为了增强适应性,TPU v2将两个原本独立的缓冲区进行了重新布局,将它们合并成了一个向量存储区。这一调整使得TPU的可编程性得到了提升,并且与传统的内存结构更为相似,从而使得操作变得更加便捷和高效。
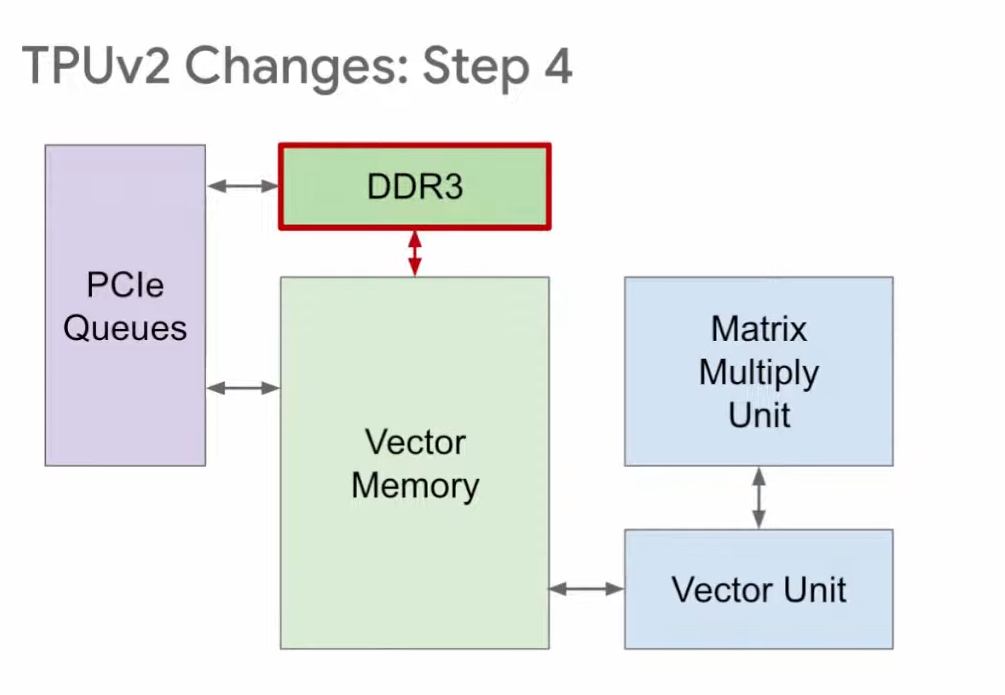
TPU训练的设计调整
训练用的TPU v2在处理上与推理环节有所区别。在训练过程中,必须进行权重的读写操作。所以,在v2版本中,我们将DDR3替换成了与向量存储区直接相连的配置。这种设计既支持数据的读取,又支持数据的写入,完全符合训练环节的要求。
TPU的关键任务
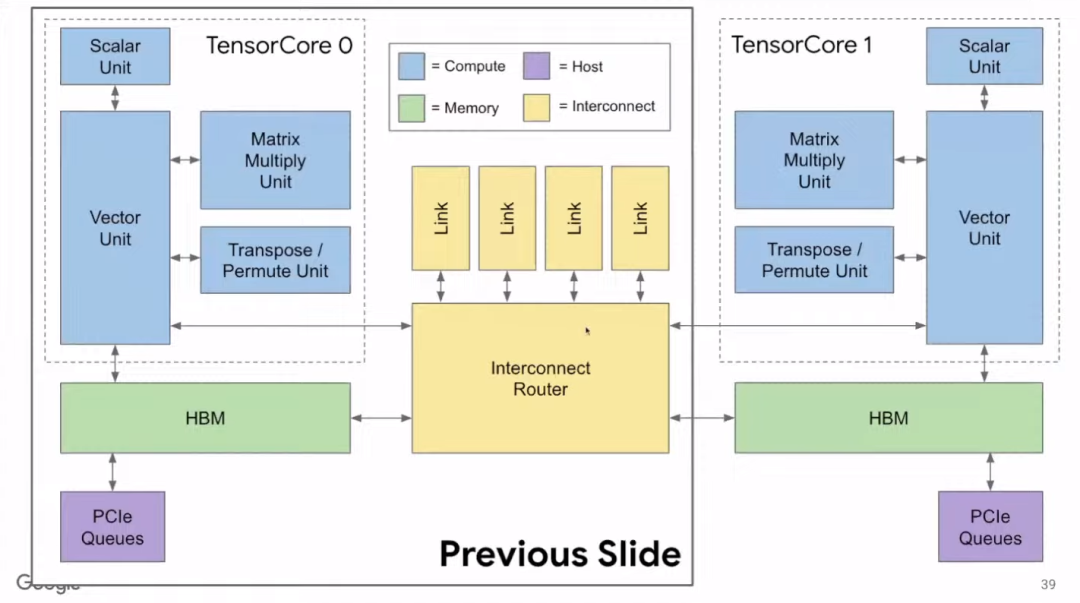
TPU的核心职能在于使各类机器在编译器看来毫无二致,如此在代码重构过程中,能够保证产出同等的高品质成果,进而实现向后兼容机器学习。这一特性保证了各机器上模型运行的一致性,进而增强了系统的整体稳定与可信度。
控制硬件成本考量
谷歌自主研发的硬件服务于其数据中心,其重点在于总体拥有成本,这包括资本投入和日常运营费用。在TPU v4版本中,考虑到总体拥有成本,设计时为训练型TPU v4配备了两个Tensor Core,而推理型TPU v4i则仅有一个,从而在成本和性能之间达到了一个平衡点。

朋友们,大家如何看待这些模型与硬件的持续改进与进步?你认为它们未来会在哪个领域实现更显著的突破?欢迎在评论区交流意见,同时别忘了点赞并转发这篇文章。